Hadoop分布式系统架构
Hadoop
- HDFS
- YARN
- MapReduce
HDFS
HDFS概述
- 优点
- 高容错、高可用、高扩展
- 海量数据存储
- 构建成本低、安全可靠
- 适合大规模离线批处理
- 缺点
- 不适合低延迟数据访问
- 不支持并发写入
- 不适合大量小文件存储
- 不支持文件随机修改,仅支持追加写入
HDFS架构

HDFS数据存储Block
-
Block块
- HDFS的最小存储单元
- 多Block多副本
- 文件被切分成若干个Block,每个Block都有多个副本(默认3副本)
- Block以DataNode为存储单元,即一个DataNode上只能存放Block的一个副本
- 机架感知:尽量将副本存储到不同的机架上,以提升数据的容错能力
- 副本均匀分布:DataNode的Block副本数和访问负荷要比较接近,以实现负载均衡
- Block大小
- 默认128M,可设置(若Block中数据的实际大小 < 设定值,则Block大小 = 实际数据大小)
-
Block副本放置策略(Hadoop 3.x)
-
副本1:放在Client所在节点上
对于远程Client,系统会随机选择机架和节点(最空闲)
-
副本2:放在与副本1不同的机架上
-
副本3:放在与副本2同一机架的不同节点上
-
副本N:在遵循相关原则的前提下,随机选择
-
节点选择原则
- 避免选择访问负荷太重的节点
- 避免选择存储太满的节点
- 避免将Block的所有副本都放在同一机架上
-
-
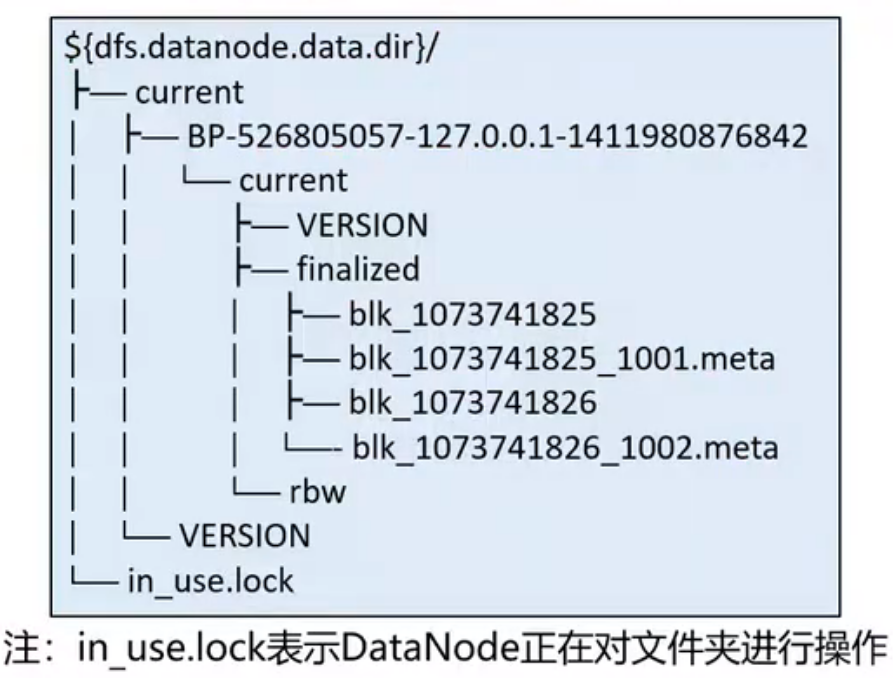
Block文件
Block文件是DataNode本地磁盘中名为“blk_blockId”的Linux文件
- DataNode在启动时自动创建存储目录,无需格式化
- DataNode的current目录下的文件名都以“blk_”为前缀
- Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成
HDFS元数据存储
-
元数据
目录文件的基本属性(如名称、所有者等)、Block相关信息(如文件包含哪些Block、Block放在哪些节点上等)、DataNode相关信息
-
内存元数据
- Active NameNode:最新的元数据(= fsimage + edits,实时更新)
- Standby NameNode:通过QJM定期(默认60s)同步AN的元数据
-
文件元数据
-
内存元数据持久化后形成的文件
-
edits(编辑日志文件)
- 保存了最近一个Checkpoint检查点之后的所有变更操作(需要定期瘦身)
- 变更操作应先写edits,再写内存
- edits文件名通过“Transaction Id前后缀“标记所包含更新操作的范围
-
fsimage(元数据检查点镜像文件)
- Standby NameNode在Checkpoint检查点定期对内存中的元数据进行持久化,生产fsimage镜像文件
- fsimage的写入速度比较慢,所以不可能对变更操作进行实时持久化
- fsimage文件名标记出最后一个变更操作的Transaction Id

-
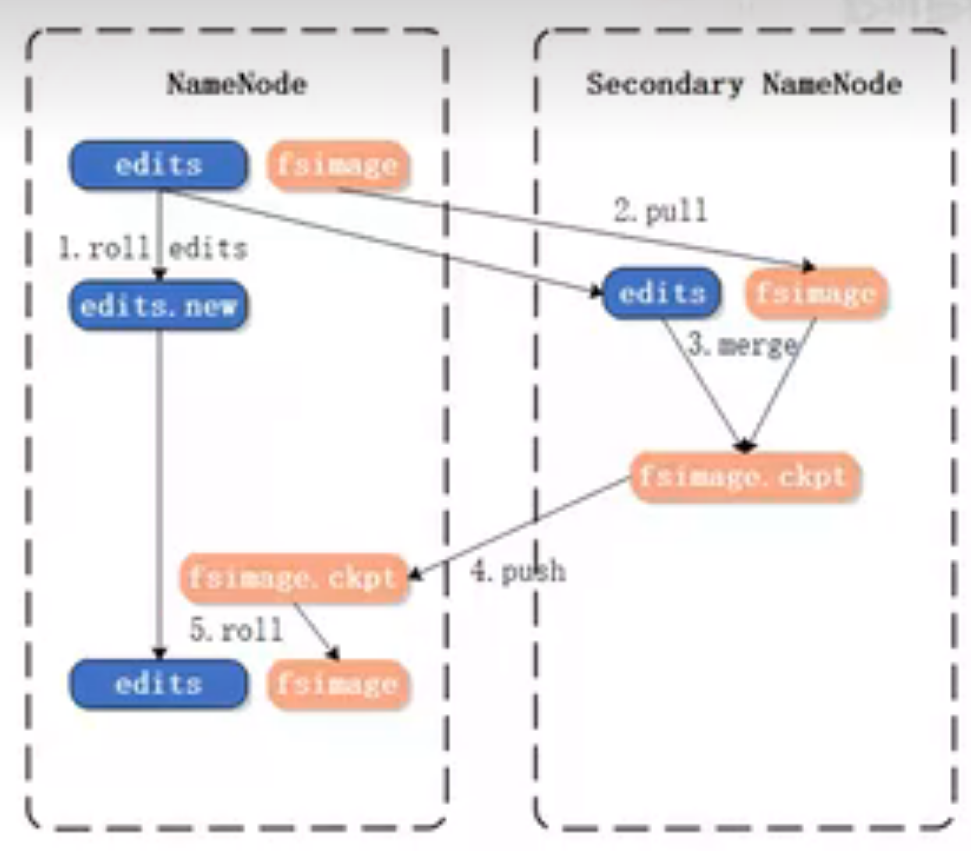
edits与fsimage持久化(Hadoop 1.x)(没有HA(高可用))
-
基于远程合并的持久化
- 在Checkpoint检查点,SN请求PN停用edits,后续变更写入edits.new
- 将fsimage和edits下载到SN(第一次需下载fsimage)
- 在内存中载入fsimage,与edits进行合并,然后生成新的fsimage,并将其上传给PN
-
缺点
- 合并前要先将fsimage载入内存,速度慢
- 未实现edits高可用(SN上的edits不是最新的),若PN上的edits损毁,将导致元数据丢失
- SN无法承担热备职能
-
-
edits与fsimage持久化(Hadoop 2.x)高可用
- QJM(Quorum Journal Manager)共享存储系统
- 基于Paxos算法实现的JournalNode集群,实现了edits的高可用存储和共享访问
- 最好部署奇数(2n + 1)个节点,最多容忍 n 个节点宕机
- 过半(>= n + 1)节点写入成功,即代表写操作完成
- 基于QJM的edits持久化
- AN将变更操作同步写入本地和QJM的edits
- 在内存中执行该操作,并将结果反馈给Client
- 基于QJM的fsimage持久化
- 在Checkpoint检查点,SN先将内存元数据变为只读来暂停QJM edits的定期同步,再将元数据镜像到fsimage中
- SN将fsimage上传到AN,同时恢复QJM定期同步
- AN根据fsimage的事务id,删除旧edits,实现瘦身

- QJM(Quorum Journal Manager)共享存储系统
-
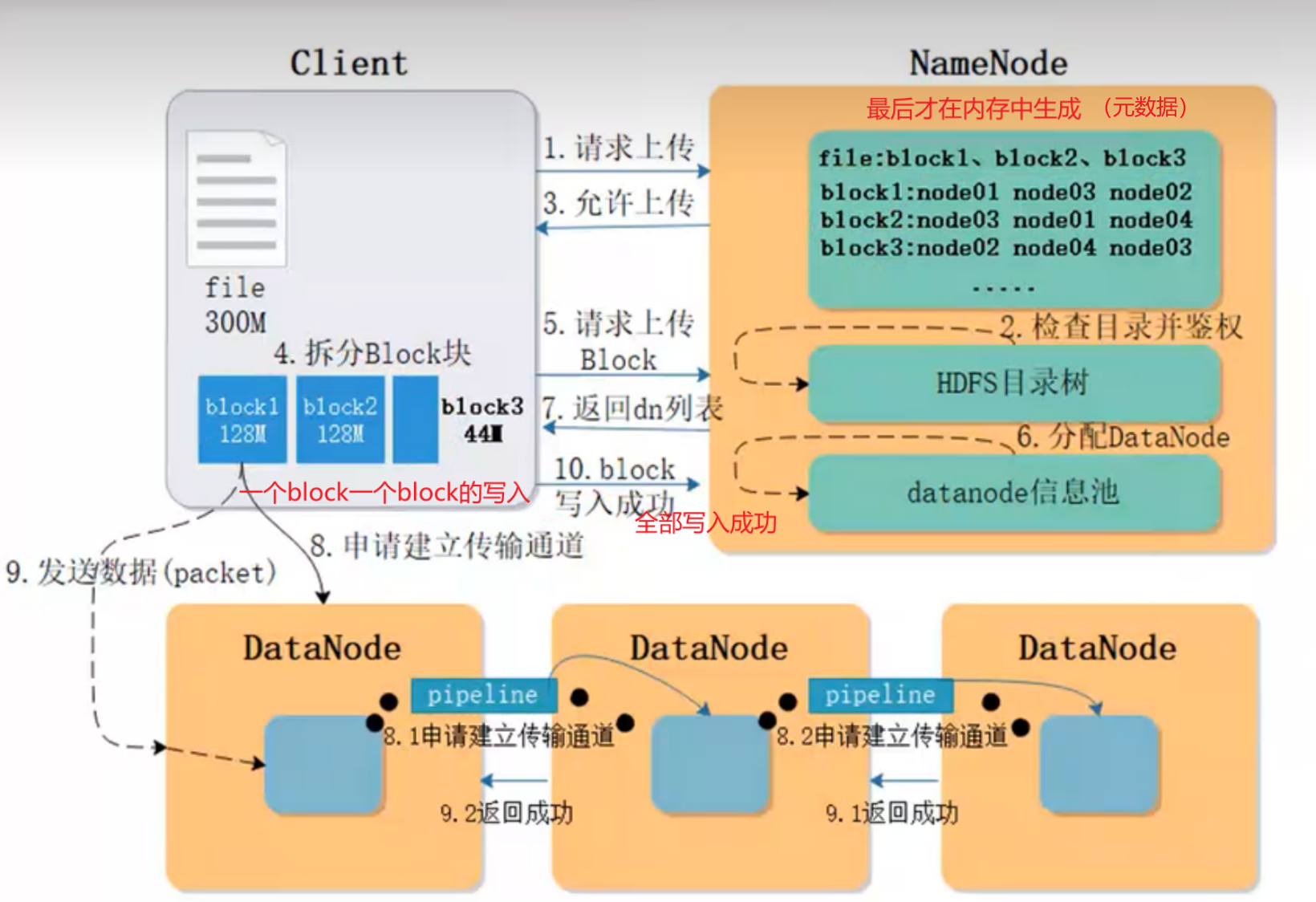
HDFS读写流程
- 写
- 读

HDFS安全模式
- 什么是安全模式
- 安全模式是HDFS的一种特殊状态,在这种状态下,HDFS只接收读数据请求,而不是接收写入、删除、修改等变更请求
- 安全模式是HDFS确保Block数据安全的一种保护机制
- Active NameNode启动时,HDFS会进入安全模式,DataNode主动向NameNode汇报可用Block列表等信息,在系统达到安全标准前,HDFS一直处于”只读“状态
- 何时正常离开安全模式
- Block上报率:DataNode上报的可用Block个数 / NameNode元数据记录的Block个数
- 当Block上报率 >= 阈值时,HDFS才能离开安全模式,默认阈值为0.999
- 不建议手动强制退出安全模式
- 触发安全模式的原因
- NameNode重启
- NameNode磁盘空间不足
- Block上报率低于阈值
- DataNode无法正常启动
- 日志中出现严重异常
- 用户操作不当,如:强制关机(特别注意)
- 故障排查
- 找到DataNode不能正常启动的原因,重启DataNode
- 清理NameNode磁盘
HDFS高可用
-
HDFS在设计上
-
优势
- 高容错性
- 扩展性
- 海量数据的高效读、写
-
劣势
-
NameNode内存受限问题
Federation机制(多个NameNode共同管理)
-
NameNode单点故障问题
对NameNode做高可用(HA)
-
-
-
Hadoop2.x中,对于HDFS中NameNode高可用提供了实现
-
集群中,提供两台NameNode做热备
- Active
- Standby
-
一台NameNode宕机,另一台如何接管集群?
-
元数据信息保持一致
edits、fsimage
-
如何做到自动的故障迁移
Zookeeper集群
-

-
HDFS基本用法
-
文件系统命令
-
语法
-
hadoop fs
使用面最广,可以操作任何文件系统
-
hadoop dfs
只能操作HDFS文件系统,已废除
-
hdfs dfs
推荐使用,hadoop fs 执行时会转换为此命令
-
大部分用法和Linux Shell类似,可通过help查看帮助
-
-
HDFS URI
-
格式:scheme://authority/path
-
示例:HDFS上的一个文件/parent/child
URI全写:hdfs://nameservice/parent/child(用nameservice替代namenodehost)
URI简写:/parent/child
需要在配置文件中定义hdfs://namenodehost
-
-
-
REST API
-
HDFS的所有接口都支持REST API
-
HDFS URI与HTTP URL
- hdfs://
:<RPC_POST>/ - http://
:<HTTP_PORT>/webhdfs/vl/ ?op=…
- hdfs://
-
写入文件
-
提交一个HTTP PUT请求,这个阶段不会传输数据,只是一个前置条件及一些设定
curl -i -X PUT "http://<HOST>:<POST>/webhdfs/vl/<PATH>?op=CREATE [&overwrite=<true|false>][&blocksize=<LONG>][&replication=<SHORT>][&permission=<OCTAL>][&buffersize=<INT>]" -
提交另一个HTTP PUT请求,并提供本地的文件路径
curl -i -X PUT - T <OCAL_FILE> "http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?op=CREATE..."
-
-
获取文件
提交HTTP GET请求
curl -i -L "http://<HOST>:<POST>/webhdfs/vl/<PATH>?op=OPEN[&offset=<LONG>][&length=<LONG>][&buffersize=<INT>]" -
删除文件
提交HTTP DELETE请求
curl -i -X DELETE"http://<HOST>:<POST>/webhdfs/vl/<PATH>?op=DELETE[&recursive=<true|false>]"
-
HDFS运维管理
-
核心配置文件
-
core-site.xml:Hadoop全局配置
-
hdfs-site.xml:HDFS局部配置
-
示例:NameNode URI配置(core-site.xml)
1 2 3 4 5 6<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://nameservice:9000</value> </property> </configuration>
-
-
环境变量文件
- Hadoop-env.sh:设置了HDFS运行所需的环境变量
YARN
YARN简介
-
MapReduce存在先天缺陷(Hadoop 1.x)
- 身兼两职:计算框架 + 资源管理框架
- JobTracker
- 既做资源管理,又做任务调度
- 任务太重,开销过大
- 存在单点故障
- 资源描述模型过于简单,资源利用率较低
- 仅把Task数量看作资源,没有考虑CPU和内存
- 强制把资源分成Map Task Slot 和 Reduce Task Slot
- 扩展性较差,集群规模上限4K
- 源码难于理解,升级维护困难
-
YARN(Yet Another Resource Negotiator)另一种资源管理器
- 分布式通用资源管理系统
- 设计目标:聚焦资源管理、通用(适用于各种计算框架)、高可用、高扩展

YARN基本架构
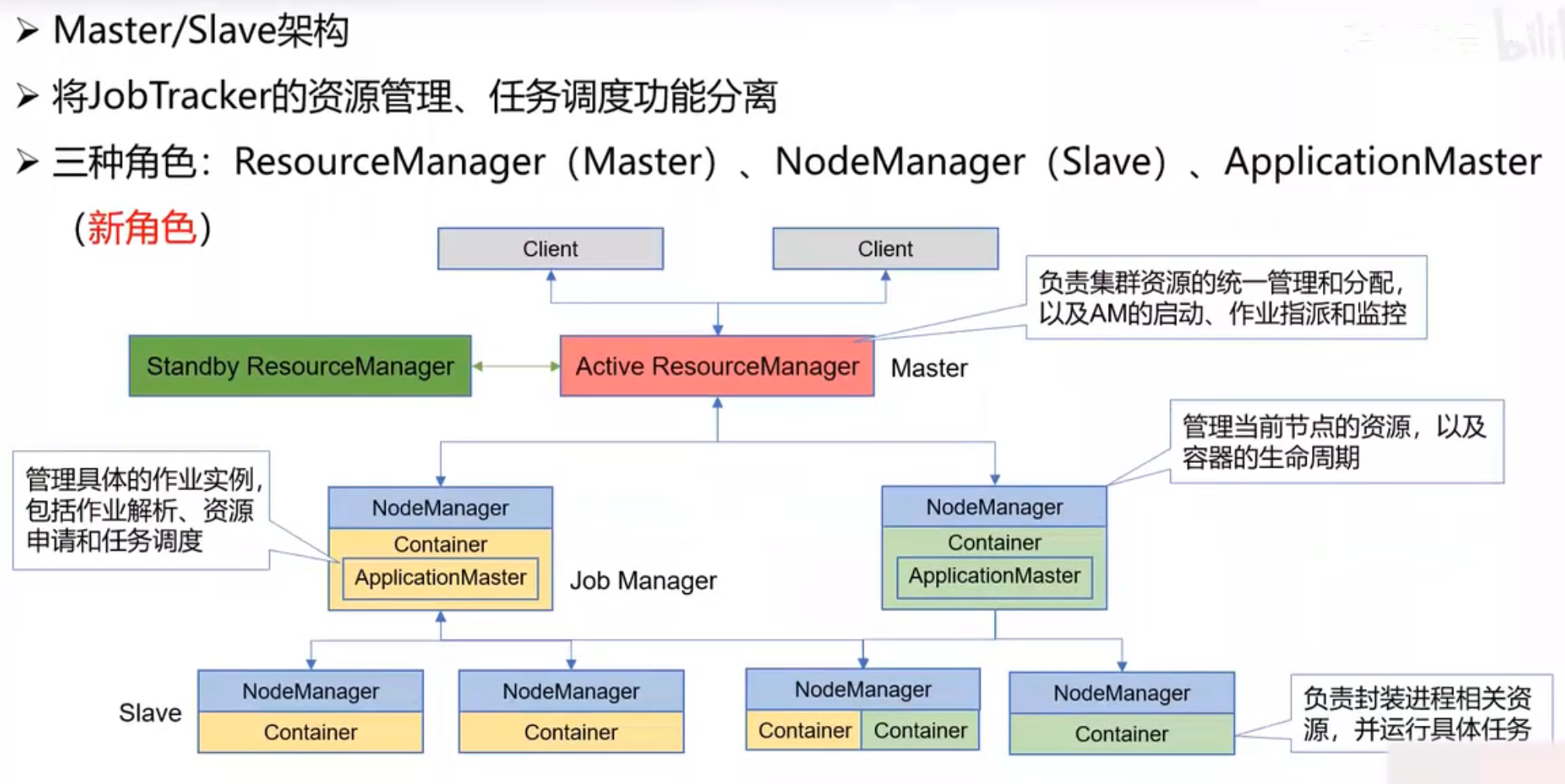
工作机制:

YARN高可用
- ResourceManager高可用
- 1个Active RM,多个Standby RM
- 宕机后自动实现主备切换
- ZooKeeper的核心作用
- Active节点选举
- 恢复Active RM的原有状态信息
- 切换方式:手动、自动

-
RM管理命令
yarn rmadmin [command_options]
YARN调度策略
-
FIFO Scheduler(先进先出调度器)
-
调度策略
- 将所有任务放入一个队列,先进队列的先获得资源,排在后面的任务只有等待
-
缺点
- 资源利用率低,无法交叉运行任务
- 灵活性差,如:紧急任务无法插队,耗时长的任务拖慢耗时短的任务
-
-
Capacity Scheduler(容量调度器)
-
核心思想:提前做预算,在预算指导下分享集群资源
-
调度策略
- 集群资源由多个队列分享
- 每个队列都要预设资源分配的比例(提前做预算)
- 空闲资源优先分配给“实际资源/预算资源”比值最低的队列
- 队列内部采用FIFO调度策略
-
特点
- 层次化的队列设计:子队列可使用父队列资源
- 容量保证:每个队列都要预设资源占比,防止资源独占
- 弹性分配:空闲资源可以分配给任意队列,当多个队列争用时,会按比例进行平衡
- 支持动态管理:可以动态管理调整队列的容量、权限等参数,也可以动态增加、暂停队列
- 访问控制:用户只能向自己的队列中提交任务,不能访问其他队列
- 多租户:多用户共享集群资源

-
-
Fair Scheduler(公平调度器)
-
调度策略
- 多队列公平共享集群资源
- 通过平分的方式,动态分配资源,无需预先设定资源分配比例
- 队列内部可配置调度策略:FIFO、Fair(默认)
-
资源抢占
- 终止其他队列的任务,使其让出所占资源,然后将资源分配给占用资源量少于最小资源量限制的队列
-
队列权重
- 当队列中有任务等待,并且集群中有空闲资源时,每个队列可以根据权重获得不同比例的空闲资源

-
YARN运维与监控
-
Shell命令
# yarn application [command_options]-list、-kill
、-status -
kill 任务
- CTRL^C不能终止任务,只能停止其在控制台的信息输出,任务仍在集群中运行
- 正确方法:先使用yarn application -list 获取进程号,再使用 -kill终止任务
-
8088
MapReduce
MapReduce简介
- 起源
- 2004年10月Google发表了MapReduce论文
- 设计初衷:解决搜索引擎中大规模网页数据的并行处理
- Hadopp MapReduce是Google MapReduce的开源实现
- MapReduce是Apache Hadoop的核心子项目
- 概念
- 面向批处理的分布式计算框架
- 一种编程模型:MapReduce程序被分为Map(映射)阶段和Reduce(化简)阶段
- 核心思想
- 分而治之,并行计算
- 移动计算,而非移动数据
- 特点
- 计算跟着数据走
- 良好的扩展性:计算能力随着节点数增加,近似线性递增
- 高容错
- 状态监控
- 适合海量数据的离线批处理
- 降低了分布式编程的门槛
- 适用场景
- 数量统计,如:网站的PV、UV统计
- 搜索引擎构建索引
- 海量数据查询
- 复杂数据分析算法实现
- 不适用场景
- OLAP
- 要求毫秒或秒级返回结果
- 流计算
- 流计算的输入数据集是动态的,而MapReduce是静态的
- DAG计算(有向无环图)
- 多个作业存在依赖关系,后一个的输入是前一个的输出,构成有向无环图DAG
- 每个MapReduce作业的输出结果都会落盘,造成大量磁盘IO,导致性能非常低下
- OLAP
MapReduce词频统计原理

MapReduce运行原理

map task - reduce task
map - shuffle -reduce
shuffle详解
